 _
_Viewed 323 times | words: 3979
Published on 2024-03-03 22:30:00 | words: 3979

After two parallel series of "monster articles" (as each one contained at least one with more than 10,000 words), time to get back to the theme of interacting with audiences.
Something that was actually part of the theme of the previous article within this book drafting series.
In this article, will share progress on some publication activities, and associated datasets, also if, for the time being, while I will keep working on some material, no further update will be released as either a dataset or webapp, and will just start using in future articles some of the material developed.
But before the article itself, a bit of contextualization.
The first draft of this article contained a longer contextualization that was rehashing some concepts that I already shared.
In reality, was more for local audiences (i.e. tribes).
Hence, once shared locally in the draft, simply shifted it into a collection of "components" that will use in future publications.
I released today my latest CV update, and the presentation was: end of a few experiments, and next step on few publications; hence, released an updated CV- always focused on change, FTC/temp-to-perm, but always "mission-based"
covering activities since 1986
chronological history: see robertolofaro.com/cv
An experiment should, in my view and experience, treated as it if were the real thing- learned that in politics and then the Army, and "embedded" that concept whenever designing and delivering training courses.
Ditto when I was asked to deliver training courses using pre-existing material: I always have to embed a "touch of contact with reality".
Somebody today went to read a book review that posted few years ago, on an old book that found on a used book stand AA.VV. - Norme per l'organizzazione la direzione e lo svolgimento delle esercitazioni n. 5032 - ISBN none - 3.5/5- yes, about the organizational and oversight side of field training exercises.
Because if you do an experiment, the idea is that you might have to learn from it, maybe repeat, or maybe adjust to improve.
In each case, you need to have defined, before starting, a series of procedures, measures, etc.
Otherwise, you are not doing experiments or exercises- you are randomly poking reality.
The key element? My local experiments included checking again, after 2018, if it was feasible to actually develop something locally: I collected some more information that could be useful in the future, but frankly confirmed what I saw in 2018.
Or: developed my experience since the 1980s mainly outside the territory and with business and social interactions abroad, first occasional, the continuously (between when I moved abroad in 1997 and started again being local and working locally in 2012).
Hence, if it is on missions, fine- but in a tribal society the idea that you can work with a tribe on a mission, and in parallel work on other missions for other tribes, is still something unimaginable.
To make a long story short: how does somebody born in Italy, notoriously a tribal society where everything is filtered through tribal lenses, develop a data-centric and context-assessment view, despite all the social pressure (a.k.a. mobbing) to conform to whatever tribal pigeonholing somebody else identified?
First and foremost, by living across Italy and its tribes, and starting early to look at the sources of whatever information is provided, as soon as something provided before is proved to be either misleading or just plainly distorted for tribal purposes.
Now, this is the end of the "contextualization part" of this article (the one that I publish for now), what you will read in the next few sections has the following characteristics:
_ potentially highly boring and "technical" in different domains
_ it is not a set of announces, but a set of "where we are", i.e what I have already done
_ shares potential next steps- potential- as Eisenhower reportedly said/wrote, no plan survives contact with reality
_ will result in further free material shared online, for each item discussed
_ is of course part of ongoing research execution and book publishing preparation activities.
The sections within this article start with a general introduction about the concepts shared across each "theme", followed by a short discussion (and, in a couple of cases, quantitative information) about the progress across five main themes, followed by a "conclusions" section that is really a kind of "if you want to know more":
_ converging efforts: common threads
_ lessons learned building an easier way to access public textual information
_ global sustainability convergence and European Union initiatives
_ looking under the hood- what few dozens annual reports can tell
_ when the impacts of technology transcend technologists and regulators
_ a local case- Italian political and social communication in Italy
_ conclusions- moving forward.
Converging efforts: common threads
Being this article just a kind of "progress report", this section is an introductory summary of the structure of the other sections.
In 2018 prepared on this website some search facilities using R as a statistical tool.
The idea was that it was the right time to update and upgrade my data-related skills, after completing a 2-years mission where I had to work across multiple areas, and had the opportunity to use again more of those "change, with and without technology" skills that what was officially told when offered the project in early summer 2015.
The difference with the 1980s and 1990s was that since mid-2010s there were increasingly good, accessible, and continuously update open source (and free) tools.
Also, by 2018, instead of considering how powerful should be your computer to do some of the number crunching, you could actually use (again, free) cloud-based technologies: hence, started using for various tests (and for learning) both GitHub for publications and Kaggle for hands-on learning of AI and number crunching/visualization with the new tools.
Moreover, by 2018 had become affordable also something close to the "vectorial facilities" within the old Playstation2 Emotion Engine, and on-chip support for neural networks (e.g. purchased for slightly more than 80 EUR a USB Movidius).
Last but not least, those open source tools had improved also their use of disk space and memory, so I could cheaply focus an old heavy notebook from 2012 by eventually adding memory and an SSD (then two, removing the DVD drive) on Linux for number crunching and AI purposes.
Yes, my models were mainly prototypes and concepts, as well as learning tools, a kind of "let's replace or at least put side-by-side with Excel and Access".
Tools of the trade that are now firmly part of my publishing and writing- along with the traditional Microsoft Office, also a Mysql-PHP-Apache-Sqlite-R machine, and a continuouly evolving Jupyter Notebook environment with Python (for some courses, had to use also the IBM Quantum Computing similuted environment), plus the cloud-based elements that integrate as links within the articles, and other tools (including some physical electronics- more about this in a future publication).
You probably already saw it online, if you visited some of the webapps embedded within this website, or read some of the articles or minibooks published since 2012- but the concept is that a mix of tools makes sense only if you use them if, when, how is supporting the main aim- not just because you have the tools available.
The next five sections will each discuss the status of a different data product- through something that you can see online, for most of them.
The concept is simple: except when and where really needed (e.g. to "explain" how a model produces its results), whatever tool you use should be "embedded" to support the storytelling- not be the focus of the storytelling.
Of course... unless you sell the tool or related services (something I did in the past, in few languages and for few companies- including my own).
Therefore... I will not talk about technologies and tools within the next sections of this article, only about the story relevant to each data product in each section.
Consider each data product and associated project activities (or projects that will include the results) as part of a "portfolio" of activities whose purpose is to support my personal strategic aim: "change, with and without technology".
Lessons learned building an easier way to access public textual information
If you were to visit the ECB Speeches page, it would tell you:
This application contains 3784 records : 108 blog posts 77 ECB Podcasts 539 interviews 276 press conferences 2784 speeches
items released between 1997-02-07 and 2024-02-26
Actually, it is not true: for the first few years until the Euro was released and one year later (i.e. 1997-2003), and from when also the ECB blog has been published (i.e. 2020), it contains also the press releases- some 790 of them.
This webapp has been online since 2019: it was the first one that released on a dataset, after testing the concepts since 2018 on my own articles and books.
Why this webapp? Not just because I worked on banking projects from 1987 until 2007, and then, when moved to Brussels, actually the first projects I was offered were in banking, the first one (that I turned down) for a post-M&A organizational integration.
And not even because I kept having a look on updates, just in case I had to work in that industry again.
And not even because there are so many public datasets and documents (e.g. from Basel and Frankfurt), that it can be useful to keep skills alive.
No, the reason was much simpler: after following training in 2018-2019 on tools to replace paid tools that I had used in the past, and testing on my website, was going to build a text dataset across a timeline.
While I was working on building one that had a structured and harmonized content, and that kept being updated regularly, ECB announced that was going to release, as a one-off, a dataset containing speeches.
I went online, cross-checked, downloaded, selected some "data columns" and then... went online to look at the PR website.
And there I saw that it was even more structure, but there was no search facility across all the sections.
Hence, I decided to do two things:
_ add other sections, not just speeches
_ update it regularly.
Initially, I updated it less frequently, but eventually became a weekly update, and also the ECB eventually updated the dataset on a monthly basis.
So, we had three parallel lines of evolution:
_ a daily refresh on their website
_ a weekly refresh on my webapp
_ their monthly much larger but focused just on speeches.
Also, the content of their website evolved, adding over time first a blog, then a podcast.
For now, my webapp contains just textual information (i.e. the narrative about each podcast release, but not its transcript).
Anyway, also due to space limitations, the webapp actually is based on the textual information, but contains frequency analysis information.
Imperfect, but the same that eventually started releasing weekly on Kaggle, to help others who might be interested, and maybe integrate with the original monthly ECB update to produce something more advanced, such as contextual search (and not just the multiple keywords, or keywords initial parts, that my webapp provides.
Example: you could use the webapp to look for "digital euro", obtaining so the list of who published something and in which year, as in this picture:

Then, could use the links provided to actually access the sources, and download them, whatever they are (speeches, interviews, blog, podcast), and use that material for e.g. see the evolution of the position of the ECB from when the only hints were negative discussions about cryptocurrency such as Bitcoin, to when it became a possibility, then started collecting opinions, then prepared plans, and, more recently, started sharing ideas to replicate to potential objections from within the banking industry about the impacts on banking of a digital euro.
In my case, the webapp and the associated dataset will evolve, but this is just a progress report- hence, here you have it.
Global sustainability convergence and European Union initiatives
Since 2020 published curated datasets and analysis articles on UN SDGs, NextGenerationEU, and the associated Italian PNRR.
It would be diffidult to summarize here the information shared online, so I better redirect to three areas:
_ on this website, where datasets and associated files and webapps are listed
_ on Kaggle, where I keep posting datasets and often also an associated presentation notebook
_ on GitHub, where I share instead documents or document collections.
It is interesting to see how, even recently, in webinars, workshops, presentations the connection between the UN SDG, harmonization on them at the EU level, and the actual national recovery and resilience plans is often lost.
Still, it was within the working papers prepared along with the recovery and resilience facility and reviews of each EU Member State national recovery and resilience plan that was presented the "roadmap" on where the EU was, where aimed to be, and where each EU Member State was.
Actually, I suggest to visit two websites, just to have an overview:
_ the site describing the UN SDGs and linking to other information facilities (the profiles for each country are here)
_ the recovery and resilience scoreboard.
As an example, this is the UN SDGs profile for Italy:
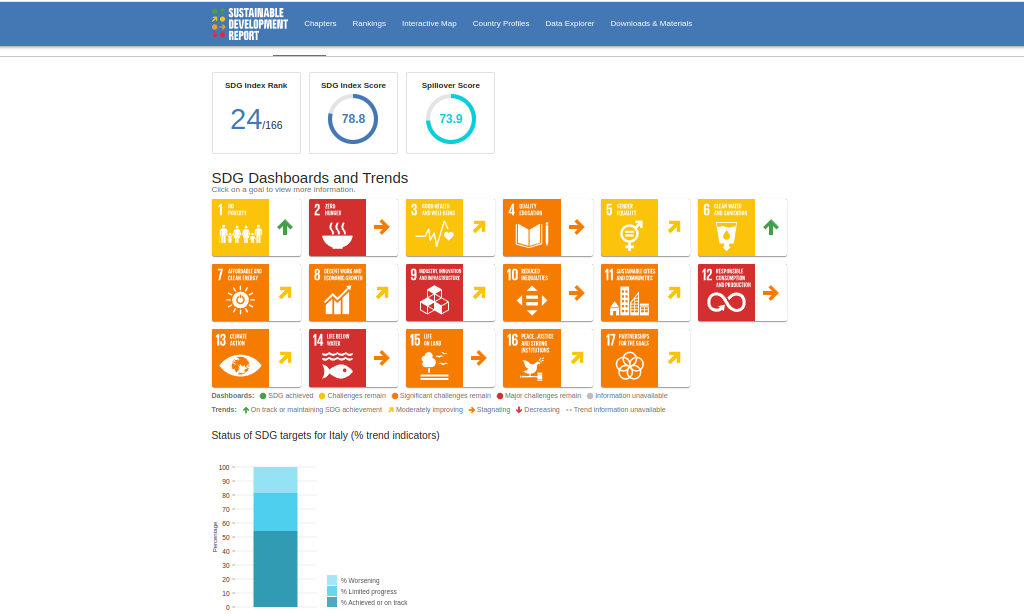
And this is the recovery and resilience facility / national recovery and resilience facility scoreboard
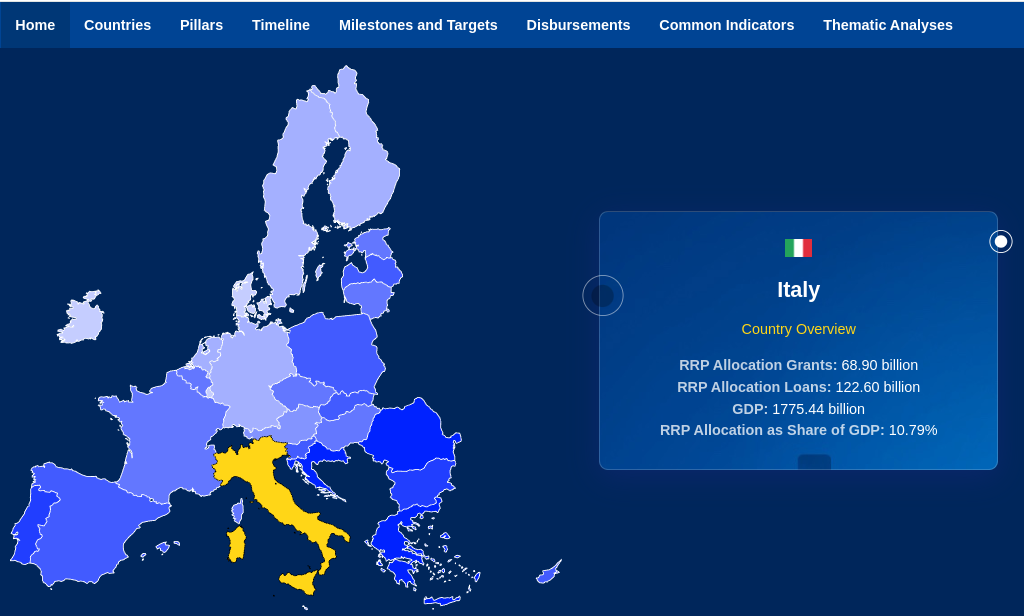
As of March 2024, all the datasets associated with this section are "static", as I am working on analysis and data update.
Looking under the hood- what few dozens annual reports can tell
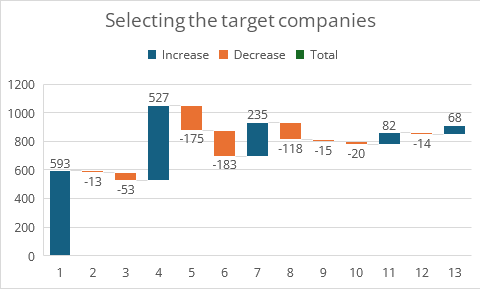
Since 2022 worked on a data-project on the balance sheets of selected companies listed on BorsaItaliana pre- and post-COVID, selecting 237 (the 235, as companies were delisted) out of the 593 on Borsa Italiana.
If you followed prior announces, or even just visited the Borsa Italiana Listino 2023-07-11, upd 2024-02-23, you know that, since summer 2022, this project went through various steps.
The key concept was comparing companies listed on Borsa Italian in 2019 and 2021 (i.e. pre- and post-COVID), looking at annual reports.
The reason for choosing those listed was to have a degree of "filtering" on annual reports and overall company compliance.
The selection criterias were all about transparency, and each step simply checked yet another element.
It would be too long to discuss the steps, so I will just share two pictures:
_ the quantitative side, i.e. how many companies were part of each selection up to the current 68 starting with the initial 593
_ the qualitative side, i.e. what was used in each step.

When the impacts of technology transcend technologists and regulators
I think that anybody reading newspapers or watching news should now be aware that AI has at least two characteristics that make it different:
_ is able to "learn" from data and self-adjust
_ is able to process massive amount of data with a speed no human can match.
There is another element worth considering: as cloud-based computing removes access barriers to computing facilities, and smaller and smaller smarter devices make it feasible to have also "local" AI interacting with the cloud only when is needeed, i.e. keeping data but also processing of the data local (yes, "edge computing").
In a data-centric society where everybody generates and consumes data continuously (what you are doing by just reading this article so far is also providing to your connection method information of what you watch and for how long), all these elements together, as I wrote in previous articles, require a different approach to both regulation and compliance.
It is still too early to see what the blend of politics and technology have in store for us, if they will increase or reduce our freedom, but on the data privacy side frankly I am more inclined toward what Arthur Clarke described in one of his books.
Our current approach to data privacy preserved through regulatory approaches (e.g. anonymization) probably will not resist the evolutions of self-improving AI that can connect countless sources of data and cross-reference/integrate them.
Hence, it is interesting to watch at the data side of society and the evolution of both technology and regulatory approaches by looking from the "street level", i.e. operational information provided by those on the frontline of society, business, technology.
Since 2023 published a search engine on AI Ethics papers published on arXiv, updated monthly (mid of the month).
It all started by chance- had so select a subject for an essay contest on Kaggle, and selected AI ethics.
Reason? Beside using it within the contest, it is a subject relevant to my research needs, as I had to consider data ethics and privacy since my first official projects in the late 1980s.
Anyway, doing the work to prepare that essay implied reading what I found- and it was interesting.
Considering that many articles I read about data privacy and data ethics (not just limited to AI) were somewhat superficial, decided that could be interesting doing a monthly update.
Currently the AI ethics primer is yet another webapp that goes through 151 papers and 3308 pages, latest updated on 2024-02-11, next one will have reference date 2024-03-11, and will be published within the following week-end.
A local case- Italian political and social communication in Italy
This is the shortest section, as it is more a description of an ongoing project and its scope, than a data product already defined as prototype or even released.
In Italy we have a change of government not too long ago.
I shared since then in various articles my feed-back on the communication approaches, both on the political and social side, that have been visible through news.
After watching at the evolution since the latest national elections, decided that would be interesting to have a more structured approach, by collecting and then analyzing news items continuously, so that a "quantitative" as well as a "qualitative" element might be blended.
Since summer 2023 have been working on data preparation and review for an ongoing study on political and social communication in Italy.
For now, beside designing the "container" for the information and revising the documentation collected, it is still a project and not yet a data product (except for a data collection database).
Anyway, will keep evolving across spring.
Conclusions- moving forward
Yes, I keep once in a while writing about that forthcoming second volume of QuPlan.
The idea is that this second volume will actually follow the publication of mini-books about some of the data products described above, plus others that already shared about online.
Therefore, few weeks ago prepared the reference structure to present each data product and data project, information that will share
I would be interested in getting feed-back about articles etc, but:
_ if you have commentary, contact me on Linkedin
_ if you have questions, remember that I will share questions and answers online for all to see; if you want to be anonymous, just state so
Be constructive- if you want to complain, start a conversation, etc... please, I have no time.
I think that it is more productive to share my ongoing material or position papers as contributions, and let others do whatever they see fit.
What is my angle? Keeping skills alive and finding new dots to connect, while potentially having others who, for their own "angle", would explore strengths and weaknesses: yes, the old "win-win" or, better, getting a smaller slice of a larger pie.
Of course: if it is a business issue, then if you are a customer we can build a project or initiative around it- but I can provide time and experience if you can provide budget and resources.
In the future, once settled somewhere, I could do as I did in both London and Brussels, i.e. use part of my proceeds to integrate others who have time and experience but lack budget and resources.
Of course along with others: taking ownership 100% of the risk of somebody else's business is never advisable, and ended up unwillingly "been there, done that", and in Italy since the early 2000s routinely had to fend off similar "tremendous opportunities"- something worth another article on how to "manage your own filtering of tremendous opportunities".
And, yes, in the past, and not just in Italy, I also advised (often for free) others, before or after they had taken on "tremendous opportunities" but had not understood the context, about the risks.
And, furthermore, more than once I was then asked to help them wrangle out of tremendous opportunities that in a mist of a mix of hybris, narcissism ("I know better hence I will play these idiots whenever I want"), they had taken on, and were bleeding them dry.
I will publish another book blog update article in few months, but meanwhile will keep publishing articles about other subjects and, whenever relevant, new or updated datasets, webapps, mini-books.
For now... have a nice week!